You should develop your own collection of shell techniques.
There are so many things you can do by gluing simple UNIX commands
together into pipelines, and experienced hackers have their own
collection of favorites.
I will present some of mine in this chapter, but remember that you
should use these as a starting point for developing your own set.
Jake spent a full hour with Alien, side by side. They began with
her core programming tools, customizing Emacs and GDB, her editor
and debugger, and then moved on to the operating system environment
itself.
Along the way he kept stopping and correcting her, half driving
instructor, half drill sergeant.
“Do it right,” Jake ordered when Alien used the left arrow key to
move to the beginning of a line of text. “Is that the most
efficient way to do it?”
“No…,” she said, without yet knowing how to improve. “Is there a
better way?”
“Control-A goes to the beginning of the line,”, Jake said. “You
don’t have to hold down the arrow key.”
“Okay.” Alien tried the command, and her cursor shot over. “Got
it,” she said. And then they continued.
“Back a line,” Jake tested her afterward.
“Forward to line one hundred and twenty-nine.
“Switch windows.
“Save buffers.
“Merge files.
“Compile.
“Good.”
“You’re a slave driver in a poncho,” Alien joked. But she
appreciated that Jake’s instructions, especially when taken
together, changed the relationship between herself and what was
happening on the screen.
The more he pushed her, the faster and
more elegantly she moved, until the commands at hand felt hers –
extensions of Alien’s body – to be used intuitively, as the
challenge at hand demanded.
This was hacking of a kind, not in the sense of breaking into
something, but of moving from outsider to insider, user to ace.
She was surprised to feel a similar thrill, in its own way as
energizing as scaling down an elevator shaft or the Great Dome.
Finally, Alien had the keyboard shortcuts down well enough to dance
across anything onscreen in seconds.
Jake looked on approvingly.
“Now you’re ready to work,” he said.
—Jeremy Smith ‘Breaking and Entering: the Extraordinary Story of
a Hacker Called “alien”’
The Bourne Shell /bin/sh was part of the original UNIX system and a
wonderful invention, which allowed redirection and pipes. It also had
control structures so you can write extensive prorams with the shell.
I do not recommend doing so: I feel that shell scripts should be
brief.
The classic example of new things that people can do with the shell is
pipelines. Here’s an example.
Let us say you want to find all the words in English that have the
string “per” in them. You can do this with:
$ grepper/usr/share/dict/words
Now you want to count how many words there are:
$ grepper/usr/share/dict/words|wc
(this last command takes the output of grep and uses it as input to
the command “wc” which counts the lines, words and chars in its input
– I get approximately 1424 words when I run it)
Now let’s say you want to find words that start with the string
“per” as a prefix:
Try the same with other strings that appear in many words, like “anti”
and “super”.
5.2.2. The evolution of the shell, leading up to bash
Then came the C shell /bin/csh, which was a “wrong turn”: it tried
to be more C-like in its script syntax, but the language spec was
confusing and sometimes ill-defined for scripting.
The shell most commonly used today is probably the Bourne Again Shell
/bin/bash. bash can run shell scripts from the traditinal /bin/sh,
but it adds some very nice features that can make users very fast.
I like to demonstrate using emacs keys to manipulate the command line
and search and edit my history. This is a real joy for me in bash.
5.3. A basic set of shell commands you should always know
All of these commands are designed to work well with pipelines. Here
I put the “classics”: programs that came with the original UNIX
distribution, or soon after. There are many much more modern commands
I use in my everyday life, and you will see some of them mentioned in
various examples below.
/bin/sh
The Bourne shell. You should limit your scripts strictly to using
its syntax.
grep
Search for patterns in files.
sed
The “stream editor”: edits a stream of text in a pipeline.
awk
awk can do anything in the world. I usually just use it for
parsing out columns of data in a stream.
cat
“Concatentates” one or more files.
wc
Counts the lines, words, and characters in a file.
less
A “file pager”: shows one screenful of text at a time, so you can
read it.
head, tail
Show the first few or last few lines of a file.
wget
“Offline browser” - grabs URLs in various ways.
man
Shows the “man page” for a command or a library function. This is
a good resource to get a reference on the various command line
options, and possibly on detailed semantics. On the other hand
they are usually not written pedagogically.
I mentioned the grep command earlier, and I also briefly mentioned
regular expressions. These can be put together quite nicely to help
with the popular word-guessing game wordle.
Note that you should not use this if you are trying to play the game;
just use it to learn some shell technique. Picking one
free/open-source wordle clone “hello wordl” at https://hellowordl.net/
we get something like this:
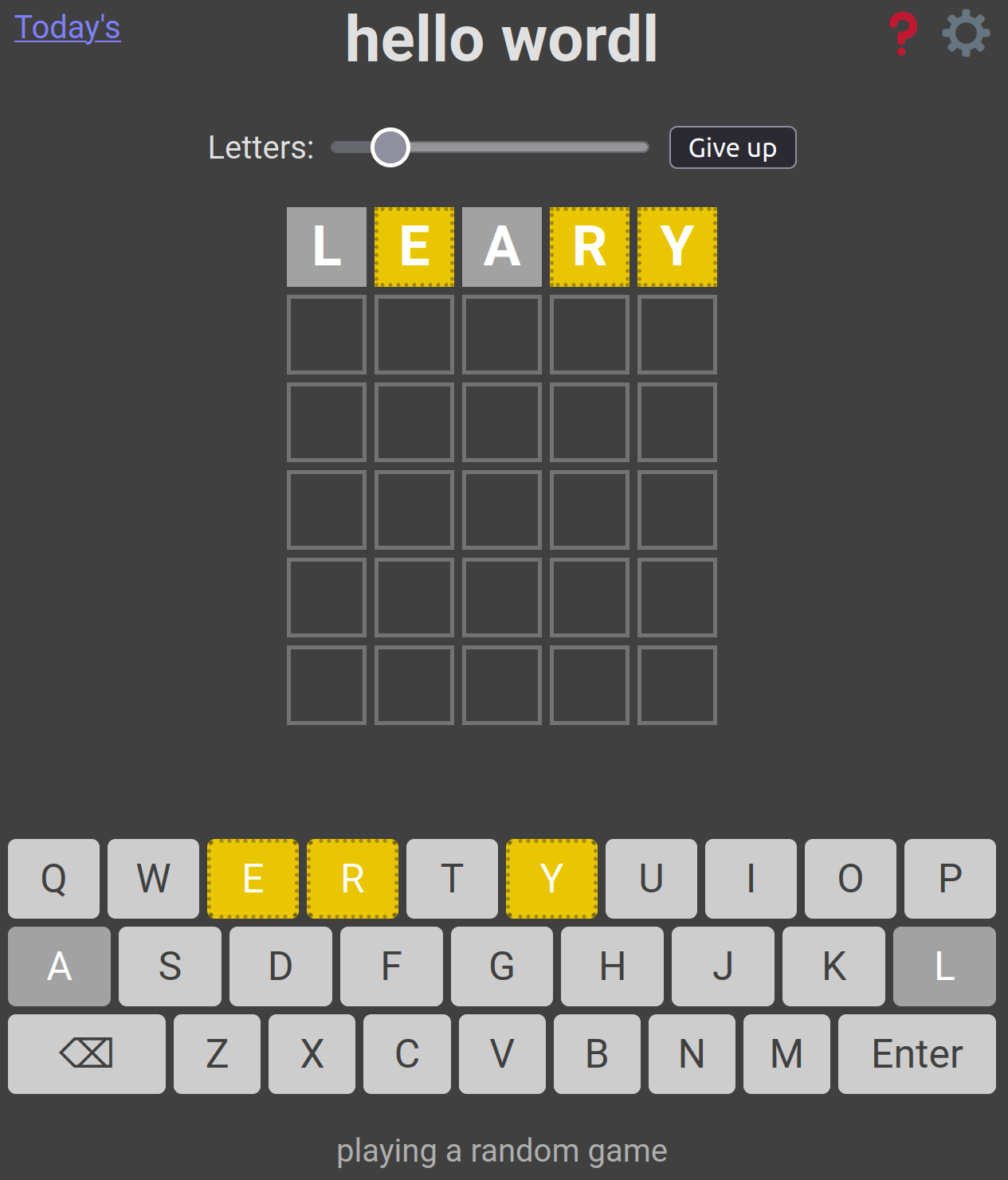
My first guess of leary gives:
My goal now is to see if I can use the grep command cleverly to
help me make my next guess.
First of all, let us find all the 5-letter words:
$ grep'^.....$'/usr/share/dict/words
This has a lot of extraneous stuff; we can improve with:
Now I can use the information from my first guess - I need ‘e’, ‘r’,
and ‘y’, but not in the positions you see in the figure, since they
are colored yellow instead of green. We also can exclude ‘l’ and ‘a’.
Start by requiring e, r, y and forbidding l and a entirely:
grep '^[a-z][a-z][a-z][a-z][a-z]$' /usr/share/dict/words | grep e | grep r | grep y | grep -v l | grep -v a | wc
This gives 31 possible words, but we can do better:
We can exclude those letters at the positions we know they are not in
we can use, for the letter ‘e’, something like grep-v'.e...' and
the command (with its output of 18 words) becomes:
Three seem possible: buyer, dryer, shyer (the others seem obscure).
Trying “buyer”:
which in this case was the correct guess.
5.4.2. View images with a fast and flexible diretory-based image viewer
In the “Serious programming small courses” book I introduced the
concept of photo collection management [FIXME: maybe I should use
photo collection management tools to this book]. Here we want to
simply have an agile program to navigate through some directories to
find files.
The program I like to use for this is geeqie (formerly called
gqview). So let us start by installing geeqie:
$ sudoaptinstallgeeqie
(question: have you ever gotten sick of apt asking you to confirm
that you want to do the installation? have you found out the command
line option -y for apt yet?)
Now run geeqie on a directory where you have a bunch of images.
Note that it does a very good job of looking at absolutely huge
pictures.
I have configured some settings in geeqie: I turned on automatic
zooming to fit the image to the window when I resize it, and I have it
show a narrow left pane with thumbnails and a big central pane with
the current image. You can also experiment with the keybindings: a
lot can be done on the keyboard, and the menus show you how. A useful
one is rapid rotation of the image with [ and ].
And if you don’t have a collection of images, let’s grab one! See the
upcoming section on grabbing images from Wikimedia Commons.
5.4.3. Grab an entire directory of images from the web
Task: download many of the NASA “astronomy picture of the day” (APOD)
images. We will stick to the dark nebulae images with this command:
This takes a while, but the entire APOD archive would take a very
long time before any .jpg files start arriving. To monitor progress
open another window and do
$ cd$HOME/Pictures/nebulae
$ ls-lsat
$ geeqie.&
and view the images. Once you have enough you can hit control-c
in the terminal with the wget command to kill it.
The options we used are: -r tells wget to recursively download
links that are found, thus not stopping with that one web page, but
rather grabbing a real chunk of that web site. -np tells wget to
not recurse in parent directories. -nc is a noclobber option,
telling wget to not overwrite a file that has already been grabbed.
-nd tells wget to not create the whole directory hierarchy, but
rather to just put the pictures in the current directory. -Ajpg
tells wget to only grab .jpg files.
Task: convert many jpg files to pdf, for example for printing. Make
them fill the page, and keep the aspect ratio.
For this we use the program *convert* from the impressive
ImageMagick suite of graphical tools. There seems to be no end to
what convert can do.
Let us use the pictures we downloaded from the NASA astronomy picture
of the day (APOD) site.
First we have to tell the convert command to not worry about safety
issues: we are not serving these images on the web. (Quick footnote:
there is a security concern: the ImageMagick team disabled generating
PDF files by default - this is unlikely to cause you any problems if
you don’t make these files public.)
Create a file called .bash_aliases in your home directory. Here
are a couple to start with:
# find a files with a given name and print themfunctionfip(){find.-iname\*${1}\*-ls;}functionfil(){find.-iname\*${1}\*-print;}# list recently modified filesfunctionlst(){ls-lashtg${1:-.}|head-13
}
Note that the .bash_aliases file is not invoked by default when
you log in, so you should put this command early on in your
.bashrc file (which is always invoked when you log in):
$ du~
$ du-h~
$ du-sh~
$ du~|sort-n
$ sudodu-x/>/tmp/du.out&$ sort-n/tmp/du.out## repeatedly while the data accumulates
There is also a graphical program called baobab which probes disk
usage. I find it more useful to use the du/sort pipeline, also
because you can then start throwing grep in to it.
Task: download an audiobook, convert it to mp3, and split it in to
well-named mp3 files, each of which lasts about 3 minutes.
Make sure you first install ffmpeg (video/audio format converter) and
yt-dlp (which allows video/audio download) with:
$ sudoaptinstallffmpeg
$ sudoaptremoveyt-dlp# the system one is too old$ sudoaptinstallpipx# use pipx to install the up-to-date program$ pipxinstall--forceyt-dlp
Let us start with an audiobook that’s on youtube that is licensed in a
manner clear enough for us to download it. Jules Verne’s Mysterious
Island can be found at: https://www.youtube.com/watch?v=5xjYHprt8e4
The file we end up with is called something like TheMysteriousIslandPart1byJulesVERNE-AudioBook,SummaryBAC,Biography-h_SYtFmypmc.mp3 which clearly will not do, so we rename it
with
$ mv'The Mysterious Island Part 1 by Jules VERNE - AudioBook, Summary BAC, Biography-h_SYtFmypmc.mp3'Jules-Verne_The-Mysterious-Island-Part-1.mp3
these are cleanly numbered in growing order. These can be put on an
mp3 player or a smartphone to be played while walking or in a car. If
you lose your place you can find it easily in a 3-minute track, while
it is harder to do so in a file that is an hour or ten hours long.
I never became an expert at sed and awk, but I did learn a few simple
patterns. These are just the simplest things you can do: there’s so
much more, but you can quickly learn to remember these ones.
Use sed (the “stream editor”) to substitute bits of text as it goes
by.
FIXME: put example here
I use awk (named after its authors legendary Bell Labs computer
scientists Aho, Weinberger, and Kernighan) to select columns in a
stream of text.
The subject of regular expressions is a vast one. I am not an expert,
but even as a non-expert I keep a few “up my sleeve” for use in the
shell.
This section is incomplete, but it should start with matching start
and end of a line with ^ and $. Then it should mention .*
to match ranges of anything. Then include at least a couple of
complex matches and a couple of replacements with the \1 type of
mechanism. [FIXME: complete this section]
Sociologist and demographer Nancy Howell collected data on the noted
Dobe !Kung tribe of the Kalahari desert, sometimes known as the
“Bushmen”. The 538 blog has a collection of data sets, including her
data on age, height, and weight data for the !Kung.
Download the Howell file with data from the bushmen:
$ wget-O-https://www.verywellfamily.com/top-1000-baby-girl-names-2757832|lynx-stdin--dump
$ wget-O-https://www.verywellfamily.com/top-1000-baby-girl-names-2757832|lynx-stdin--dump|less
$ wget-O-https://www.verywellfamily.com/top-1000-baby-girl-names-2757832|lynx-stdin--dump|grep'. '|grep'^ *[0-9]'$ wget-O-https://www.verywellfamily.com/top-1000-baby-girl-names-2757832|lynx-stdin--dump|grep'. '|grep'^ *[0-9]'|grep-vhttp
$ wget-O-https://www.verywellfamily.com/top-1000-baby-girl-names-2757832|lynx-stdin--dump|grep'. '|grep'^ *[0-9]'|grep-vhttp|grep-vfile:|grep-vabout:
$ wget-O-https://www.verywellfamily.com/top-1000-baby-girl-names-2757832|lynx-stdin--dump|grep'. '|grep'^ *[0-9]'|grep-vhttp|grep-vfile:|grep-vabout:|grep'[0-9]\.'$ NAMES=`wget-O-https://www.verywellfamily.com/top-1000-baby-girl-names-2757832|lynx-stdin--dump|grep'. '|grep'^ *[0-9]'|grep-vhttp|grep-vfile:|grep-vabout:|grep'[0-9]\.'`$ echo$NAMES## now you can go to town on this
OK, this section doesn’t really fit in this chapter because it doesn’t
really involve the shell much. In here I should mention things like
the DISPLAY and ssh and remove execution and running programs from the
command line.
curl and wget are “offline web browsers”: commands which grab stuff
from a web site unattended: you just give the command, go away for a
while, and come back to find your data downloaded. No mouse clicking.
Although they do similar stuff, the design of command line options is
different. wget is set up to make easy single commands that mirror
part of a web site hierarchy. curl is set up so that curlURL
prints that URL to standard output, which makes it very good for shell
pipelines.
What is JSON? Short for JavaScript Object Notation, JSON has taken
the world of web programming by storm. The idea is to convert a chunk
of data from any language into its javascript representation, pass it
around the web, and then unpack it back into another language. Python
has JSON libraries, as do most other languages now.
A bit of JSON representing the geographical address of my computer’s
IP address, for example, is:
This is not actually correct: my address is in Santa Fe, but my
current internet service provider runs traffic through Alburquerque
(Los Lunas is near Albuquerque), so the automated ways of
identifying the IP address’s geography are often rather coarse
grained.
The trick here is to look at three separate instructions. The first
two use web services:
Notice how the result of the ipvigilante.com queries is javascript
but it all runs on the same line, and is hard to read. There is a
program jq which is a JSON filter that can do a few tricks rather
easily. If you just run it with no arguments it pretty-prints the
JSON code:
Finally: we might want to just print basic geographical data, not that
whole list, so here are options to jq to print what we want. Note
that I’m showing here a different way than the backtick \` to
substitute a command output: the $(commandargs...) approach.
I would like to run grep to find strings in a whole collection of
files, let us say all the files under my home directory (recursively)
that end in ‘.py’. For example, you might want to find all the python
programs you have in which
Since you might not have a bunch of .txt files, here are some
recipes to download a bunch of text files:
This will create a huge number of files in your ~/gutenberg
directory. You will need to interrupt it with control-c at some
point. Mine is still running, and the command:
$ echoanexampleoffiglet|figlet
$ banner"have a nice day"$ cowsayheydude
$ cowsay-fdragon"Run for cover, I feel a sneeze coming on."$ cowsay-l
$ cowsay-fghostbustersWhoyouGonnaCall
$ sl
$ fortune
$ factor12103# factoring numbers? can we use this to search for Mersenne primes?$$$$factor`echo"2^7-1"|bc`;factor`echo"2^11-1"|bc`;factor`echo"2^13-1"|bc`$ pi50$ espeak"Hello Linux, where are the penguins"$ telnettowel.blinkenlights.nl
automated ascii art
$ wgethttps://upload.wikimedia.org/wikipedia/commons/2/23/Dennis_Ritchie_2011.jpg
$ ## make your terminal very big and try$ jp2a-fDennis_Ritchie_2011.jpg
$ jp2a-f--colorDennis_Ritchie_2011.jpg